JAVA多线程(三) 线程池和锁的分类
github演示代码地址:https://github.com/showkawa/springBoot_2017/tree/master/spb-demo/spb-brian-query-service/src/main/java/com/kawa/thread
1.线程池
1.1 线程池是什么
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够
带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、
调优和监控。
1.2 线程池作用
线程池是为突然大量爆发的线程设计的,通过有限的几个固定线程为大量的操作服务,减少了创建和销毁线程所需的时间,从而提高效率。
如果一个线程的时间非常长,就没必要用线程池了(不是不能作长时间操作,而是不宜),况且我们还不能控制线程池中线程的开始、挂起、和中止。
1.3 线程池的分类
JDK1.5之后加入了java.util.concurrent包,java.util.concurrent包的加入给予开发人员开发并发程序以及解决并发问题很大的帮助。这篇文章主要介绍下并发包下的Executor接口,Executor接口虽然作为一个非常旧的接口(JDK1.5 2004年发布),但是很多程序员对于其中的一些原理还是不熟悉,因此写这篇文章来介绍下Executor接口,同时巩固下自己的知识。
Executor框架的最顶层实现是ThreadPoolExecutor类,Executors工厂类中提供的newScheduledThreadPool、newFixedThreadPool、newCachedThreadPool方法其实也只是ThreadPoolExecutor的构造函数参数不同而已。通过传入不同的参数,就可以构造出适用于不同应用场景下的线程池,那么它的底层原理是怎样实现的呢,这篇就来介绍下ThreadPoolExecutor线程池的运行过程。
corePoolSize: 核心池的大小。 当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中
maximumPoolSize: 线程池最大线程数,它表示在线程池中最多能创建多少个线程;
keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止。
unit: 参数keepAliveTime的时间单位,有7种取值
Java通过Executors(jdk1.5并发包)提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
案例演示:
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序
(FIFO, LIFO, 优先级)执行
演示代码: https://github.com/showkawa/springBoot_2017/tree/master/spb-demo/spb-brian-query-service/src/main/java/com/kawa/thread/threadpool
1.4 线程池的原理
提交一个任务到线程池中,线程池的处理流程如下: 1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。
如果核心线程都在执行任务,则进入下个流程。 2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。 3、判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。

1.5 线程池的合理配置
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析: 任务的性质:CPU密集型任务,IO密集型任务和混合型任务。 任务的优先级:高,中和低。 任务的执行时间:长,中和短。 任务的依赖性:是否依赖其他系统资源,如数据库连接。
任务性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。
IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2*Ncpu。
混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,
那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。
我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。 优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先得到执行,需要注意的是如果一直有
优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。 执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。 依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,
这样才能更好的利用CPU。 CPU密集型时,任务可以少配置线程数,大概和机器的cpu核数相当,这样可以使得每个线程都在执行任务 IO密集型时,大部分线程都阻塞,故需要多配置线程数,2*cpu核数 操作系统之名称解释: 某些进程花费了绝大多数时间在计算上,而其他则在等待I/O上花费了大多是时间, 前者称为计算密集型(CPU密集型)computer-bound,后者称为I/O密集型,I/O-bound。
2.锁的分类
2.1 悲观锁
悲观锁:悲观锁悲观的认为每一次操作都会造成更新丢失问题,在每次查询时加上排他锁。 每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。 select * from xxx for update;
悲观锁的应用场景:synchronized, lock锁,mysql的行锁
mysql的行锁:
Spring的事务 声明式和编程式事务,编程式事务(begin/commit/rollback)
通过datasourceTransctionManager.begin()来申明开启事务,当执行sql时候开始加锁,遇到commit或者rollback释放锁,如果仅仅begin开启事务,没有提交,则会导致行锁,导致其他线程获取锁阻塞,默认是阻塞30秒。
2.2 乐观锁
乐观锁:乐观锁会乐观的认为每次查询都不会造成更新丢失,利用版本字段控制
2.3 公平锁和非公平锁
公平锁:比较公平,根据请求锁的顺序排列,先来请求的就先获取锁,后来获取锁就最后获取到, 采用队列存放 。
非公平锁:不是根据根据请求的顺序排列, 通过争抢的方式获取锁。
在我们的ReentramtLock,默认是非公平锁,可以通过初始化为true, 设置获取锁的方式是公平的方式。
public class LockThread implements Runnable{ private static ReentrantLock lock = new ReentrantLock(true); private static volatile long count = 0; @Override public void run() { while(count<100){ lock.lock(); if(count< 100){ add(); } lock.unlock(); } } private void add() { lock.lock(); count++; System.out.println(Thread.currentThread().getName() + " <> " + count); lock.unlock(); } public static void main(String[] args) { long startTime = System.currentTimeMillis(); ArrayList<Thread> threads = new ArrayList<>(); for (int i =0;i<10;i++){ Thread t = new Thread(new LockThread()); t.start(); threads.add(t); } threads.forEach(t-> { try { t.join(); } catch (InterruptedException ignore) { } }); System.out.println("End :" + (System.currentTimeMillis()- startTime)); } }

然而当我们初始化为new ReentrantLock(false)时,测试结果可以发现,线程1一直在执行,而且执行时间比设置为公平锁是执行时间更短
public class LockThread implements Runnable{ private static ReentrantLock lock = new ReentrantLock(false); /.../ 下面代码一样 }

所以一般情况下非公平锁效率比公平锁要高,还有我们的synchronized锁也是非公平锁。
2.4 独占锁与共享锁
独占锁:在多线程中,只允许有一个线程获取到锁,其他线程都会等待。
共享锁:多个线程可以同时持有锁,例如ReentrantReadWriteLock读写锁。读读可以共享、写写互斥、读写互斥、写读互斥。
2.5 重入锁
锁作为并发共享数据,保证一致性的工具,在JAVA平台有多种实现(如 synchronized 和 ReentrantLock等等 )。 重入锁,也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。 在JAVA环境下 ReentrantLock 和synchronized 都是可重入锁
2.6 CAS无锁机制
(1)与锁相比,使用比较交换 Compare and swap(下文简称CAS)会使程序看起来更加复杂一些。但由于其非阻塞性,它对死锁问题天生免疫,
并且,线程间的相互影响也远远比基于锁的方式要小。更为重要的是,使用无锁的方式完全没有锁竞争带来的系统开销,
也没有线程间频繁调度带来的开销,因此,它要比基于锁的方式拥有更优越的性能。
(2)无锁的好处: 第一,在高并发的情况下,它比有锁的程序拥有更好的性能;
第二,它天生就是死锁免疫的。就凭借这两个优势,就值得我们冒险尝试使用无锁的并发。
(3)CAS算法的过程是这样:它包含三个参数CAS(V,E,N): V:表示当前变量在主内存中的实际值;E:表示当前变量在当前工作线程中内存的实际值;
N:表示当前变量需要被更新的值;仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,
则当前线程什么都不做。最后,CAS返回当前V的真实值。
(4)CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作一个变量时,只有一个会胜出并成功更新,
其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,
CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
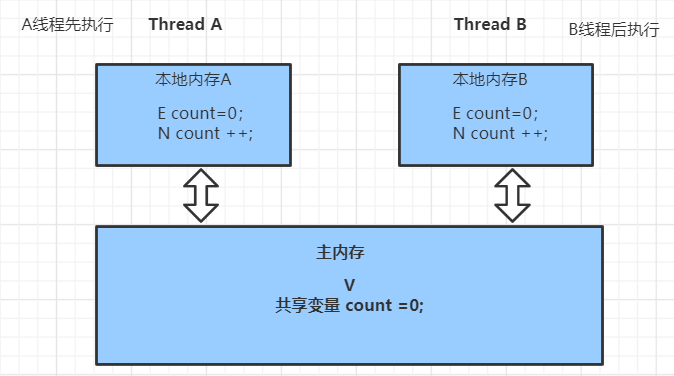
如上图所示,线程A,B 对count做操作,A线程先执行,比较 if(E ==V) 返回true,N的值赋值给V 即count =1,假如这个时候B线程后执行,比较if(E==V)返回false,说明V的值已经被改变了,然后将主内存V的值count=1刷新给E,紧接着线程B自旋操作,继续比较if(E==V)返回true,则N的值刷新的到主内存中,即count=2;
使用AtomicLong实现自增
public class LockThread implements Runnable{ private static AtomicLong count = new AtomicLong(); @Override public void run() { while(count.get()<100){ count.incrementAndGet(); System.out.println(Thread.currentThread().getName() + " <> " + count.get()); } } public static void main(String[] args) { long startTime = System.currentTimeMillis(); ArrayList<Thread> threads = new ArrayList<>(); for (int i =0;i<3;i++){ Thread t = new Thread(new LockThread()); t.start(); threads.add(t); } threads.forEach(t-> { try { t.join(); } catch (InterruptedException ignore) { } }); System.out.println("End :" + (System.currentTimeMillis()- startTime)); } }
其中incrementAndGet()方法走的 Unsafe的getAndAddLong()方法

通过debug可以发现,var6是不断通过组旋操作,保证拿到主内存中变量值,然后返回到外面,原子类AtomicLong实现自增的,也就是我们的Unsafe类的getAndAddLong()只是通过自旋保证获取主内存变量,真正的自增是在原子类里面实现的
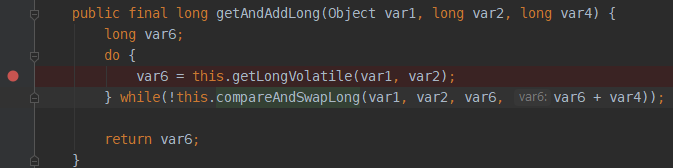
最终执行的 getLongVolatile()和 compareAndSwapLong()这两个native方,走的C++方法实现。
使用原子类AtomicLog实现CAS锁
public class LockThread { private static AtomicLong atomicLong = new AtomicLong(0); private Thread currentThread; public boolean lock() { boolean result = atomicLong.compareAndSet(0, 1); if(result) { currentThread = Thread.currentThread(); } return result; } public boolean unlock() { if(currentThread == null || currentThread != Thread.currentThread()){ return false; } return atomicLong.compareAndSet(1,0); } public static void main(String[] args) { LockThread lock = new LockThread(); IntStream.range(0,100).forEach((i) -> new Thread(() -> { try { boolean result = lock.lock(); if(result) { System.out.println("线程 <> " + Thread.currentThread().getName() + " <> 获取锁成功"); }else{ System.out.println("线程 <> " + Thread.currentThread().getName() + " <> 获取锁失败"); } } finally { lock.unlock(); } }).start()); } }

CAS ABA问题
CAS主要检查 内存值V与旧的预值值E是否一致,如果一致的情况下,则修改。
这时候会存在ABA的问题:
如果将原来的值0,改为了1,1又被改为了0发现没有发生变化,实际上已经发生了变化,所以存在ABA问题。
解决办法:通过版本号码,对每个变量更新的版本号码做+1
利用AtomicStampedReference解决ABA问题
public class AbaThread { // 注意:如果引用类型是Long、Integer、Short、Byte、Character一定一定要注意值的缓存区间! // 比如Long、Integer、Short、Byte缓存区间是在-128~127,会直接存在常量池中,而不在这个区间内对象的值则会每次都new一个对象,那么即使两个对象的值相同,CAS方法都会返回false // 先声明初始值,修改后的值和临时的值是为了保证使用CAS方法不会因为对象不一样而返回false private static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(1,0); public static void main(String[] args) { IntStream.range(0,3).forEach((i)-> new Thread(() -> { Integer reference = atomicStampedReference.getReference(); int stamp = atomicStampedReference.getStamp(); System.out.println(Thread.currentThread().getName() + " <> value: " + reference + " version: " + stamp); // 第一个参数expectedReference:表示预期值 // 第二个参数newReference:表示要更新的值 // 第三个参数expectedStamp:表示预期的版本号 // 第四个参数newStamp:表示要更新的版本号 if(atomicStampedReference.compareAndSet(reference,reference+10,0,stamp+1)) { System.out.println(Thread.currentThread().getName() + " <> 更新成功 : value: " + atomicStampedReference.getReference() + " version: "
+ atomicStampedReference.getStamp()); } else { System.out.println(Thread.currentThread().getName() + " <> 更新失败 : value: " + atomicStampedReference.getReference() + " version: "
+ atomicStampedReference.getStamp()); } }).start()); } }

